



Heptabase: 重塑知识管理与学习的未来
每个人都必须拥有 Heptabase;或者,至少体验过
我是南山居氪,致力于减弱大众对心理学的信息不对称;在少数派写一些软件体验的内容。这一次,我尝试新的写作风格,如果你喜欢的话,请在评论区告诉我。
记得那个冬天,我对双链的概念一知半解,甚至都不太了解什么是 page,什么是 database。政治哲学的笔记在我手里像烫手山芋一样,令我措手不及。政治哲学课程给我打开了明智的大门,这种思维碰撞产生的快感是前所未有的经历的。巧的是,它也让我明白了什么是双链,以及什么是链接。
在课堂上,老师的频繁提问和深思熟虑的话语使我不得不在早上 9 点钟尚未清醒之时,就开始反复记忆和回想。在寒冷阴沉的冬日清晨,即使大脑还未完全苏醒,我也必须在75分钟内持续地吸收信息并进行回顾。至于这两个过程是先后进行还是同时发生,我已经无法分辨了。
那时候,在朋友的推荐下,我知道了 Heptabase;卡片+可视化关系在当时首屈一指,随即,我也支付了。上手很简单,在白板上面只需要双击新建卡片,输入内容,再用箭头相互连接它们;或者在白板上自由的摆放位置。
我花了三个小时将所有的政治哲学笔记从 Notion 腾挪到了 Heptabase。在复制、分析和拆解这些内容时,我也对原来的笔记进行了复习和整理。完成后,卡片之间的关系以及知识核心在整理过程中逐渐显现出来。
当整理完它们,我突然发现我记住了几乎全部的内容,它们之间的联系,霍布斯和洛克对于统一概念的不同解释,相关的原句甚至是章节或者是页码,我都可以记得十分清楚。结果就是,我在课堂上经常能准确回答老师的问题,当老师在找书里原文的时候,「我们一起看书的第…页」,我也能及时提醒(因为我坐在第一排)。在后面期中期末论文写作的时候,我也竟然能够更快地写出大纲和引言,只需半天就能完成。相比以前,我的进步是非常显著的。
Heptabase 虽然前期的功能很少,但令我们驻留的原因是软件版本上的快速更新。如果没记错,内测时,我基本每周都会收到更新。现在也更新了很多功能,团队不仅对 AI 有着不凡的野心;对 Todo 而言,似乎也有着成熟的规划。
在我的使用过程中,获得了一些私人的心得,在此分享给你,希望为你带来不同的视角。
不要害怕在观点上与众不同,因为每一个现在被接受的观点曾经都是另类。
—— 伯特兰 · 罗素《自由思想的十诫》
Heptabase 的易用性几乎是领先的,引导界面结束之时,我也明白如何使用了。虽然看上去很复杂,但都错落分明,也不至于令我目不暇接和束手无策;不像其他软件一样,我得去搜视频看别人如何使用;更重要的是,我不用像使用 Notion 或者 Capacities 一样要担心设计或者分享的问题,比如 Database 如何展示或者需要考虑 Relation 等等。而 Heptabase 可以打开直接输入,不用考虑设计问题,而是直接专注在内容上,这是我非常喜欢的一点。
Most people just want to find a solution that solves their problem out of the box. Most people don’t care about all the concepts and capabilities you introduced in your system. And no matter how good your technology is, if not many people use it, you’ll end up going nowhere. So, these companies usually have to spend a lot of time working on improving usability, simplifying their product, and understanding their users’ needs.
大多数人只想找到一个能解决他们问题的解决方案。大多数人并不关心你在系统中引入的所有概念和功能。而且,无论你的技术有多好,如果没有多少人使用,你最终也会一事无成。因此,这些公司通常需要花费大量时间来提高可用性、简化产品和了解用户需求。
现在,它们也有了禅定模式(类似 flomo),我能够不受打扰得更加专注我的内容。所以,Heptabase 可能是我唯一向新手推荐的知识管理软件。也因为它的特性,各行各业的人,如医生、律师、市场、学生、历史,甚至是动画家新海诚,都能用它创作出属于自己风格或者工作流的知识管理和梳理。
这对于一个新兴软件来说,无不令人感到惊叹。

Heptabase 每个部分是什么意思?
Card,Section,Whiteboard
如果你经常用 page 这类软件如 Notion,在使用时,你可能会像我最开始一样,有可能因为分不清 Card 还是 Page 而不知道如何使用卡片,
根据上面的方法,我是这么理解 Card、Section 和 Whiteboard 的。虽然从信息密度上来看,Card<Section<Whiteboard,但是如果从层级(hierarchical)的角度来看,它们三个也可以是相同的等级。
谈到层级,我们需要回归到一个根本的问题:我们是如何分类的?或者说,我们是如何拆解概念的。
我们可能是这样拆解概念的
1829年,詹姆斯·米尔(James Mill)提出复杂想法(Complex Idea)可以是反复配对两个或更多简单感觉的结果。这些复杂想法本身还可以组合成双重想法(duplex idea)。他提出每个复杂的思想都可以分解为至少两个简单的思想(simple idea),并且通过它们不断地结合而形成。
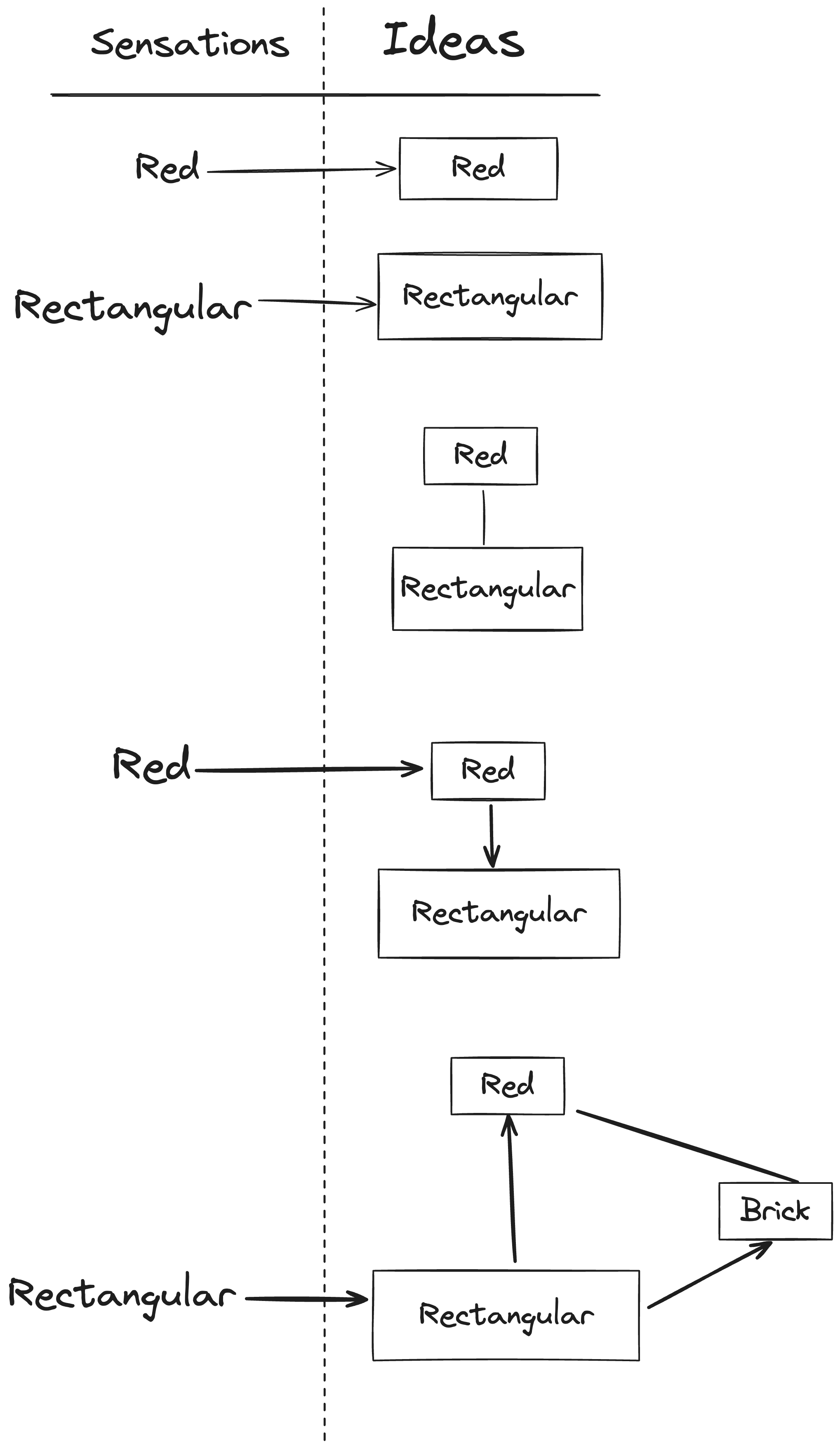
Some of the most familiar objects with which we are acquainted furnish instances of these unions of complex and duplex ideas. Brick is one complex idea, mortar is another complex idea; these ideas, with ideas of position and quantity, compose my idea of a wall. … In the same manner my complex idea of glass, and wood, and others, compose my duplex idea of a window; and these duplex ideas, united together, compose my idea of a house, which is made up of various duplex ideas.
我们最熟悉的一些对象就是这些复杂和双重观念结合的例子。砖是一个复合观念,砂浆是另一个复合观念;这些观念加上位置和数量观念,构成了我对墙的观念。......同样,我对玻璃、木头和其他东西的复合观念,构成了我对窗户的复式观念;这些复式观念结合在一起,构成了我对房子的观念,而房子是由各种复式观念构成的。
虽然这种拆分比较老套,不过也确实启发了我们对于基本概念和复杂概念的拆解。
随着世界不断发展,Mill 的理论显然不太能令人信服了,也比较过时。
我们根据从家庭或外部环境中学习的知识来对事物进行分类,这让我们能够识别对象和事件,并推断出它们的属性。首先,我们有概念(concept),即用于各种认知功能(如猫)的心理表征。
然后,我们将概念整合到类别(categories)中,这些类别是特定概念的所有可能示例。例如,「猫」这个类别包括豹、野猫和波斯猫。分类(categorization)是我们将事物放入称为类别的群组中的过程。
比如,PARA 有四种类别:项目、领域、资源、存档;我们将不同的东西放进这四个类别的过程就是分类。
类别很有用,因为它们帮助我们理解以前未遇到过的例子,并提供关于一个项目丰富的一般信息,并允许我们识别一个特定项目的特殊特征。
我们经常用下面的一些方法分类事物。
定义方法(Definitional Approach)基于对象是否符合该类别定义来确定其所属类别。例如,我们有心理学和病理学方面的字典和权威教材,以确保同一领域内专业人士之间可以共同交流。然而,这种方法效果并不理想,因为并非所有日常类别的成员都具有相同的定义特征。例如,在游戏中存在许多子类别组(如纸牌游戏和电子游戏),还有不同类型的椅子或桌子。
其次是家族相似性(Family Resemblance)是指类别中的项目在许多方面彼此相似。它解决了定义不完全涵盖所有类别成员的问题,并容许类别内部的变化。例如,椅子可以被定义为「供坐之处」和「用于支撑背部」。
另外一种方法是原型方法(Prototype Approach)。原型是一个类别的典型示例,展现了该概念成员的特征。本质上,它是对过去遇到的同类成员经验的总结。例如,并非所有鸟都像麻雀和喜鹊那样。有些鸟如猫头鹰和企鹅,也属于鸟类。
罗施(Rosch)将类别内部变异视为典型性差异所示,高典型性意味着一个类别成员与该类别原型密切相似,而低典型性则表明该成员与该分类中标准示例不太相似。
1975 年,罗施通过要求参与者评价列表中约50个成员各自代表其所属分类标题(如「鸟」或「家具」)程度来量化这一概念。参与者使用 1-7 分进行评级;其中「1」表示对该分类有出色代表性,而「7」表示不适合或非成员。他发现大多数人认为麻雀是典型的鸟类,而茶和沙发则被认为是典型的家具。
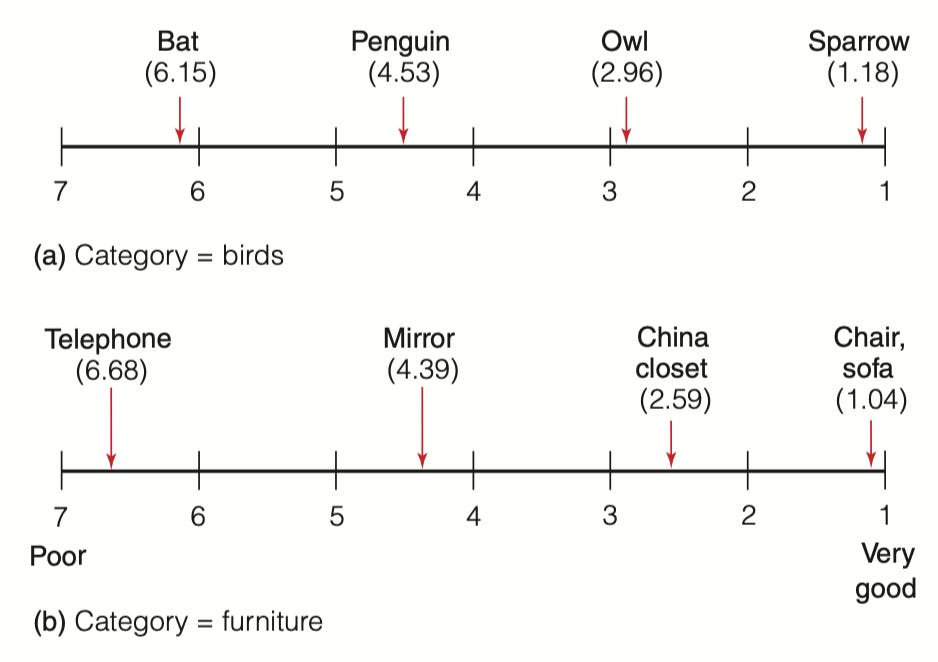
此外,罗施和默维斯(1975年)要求人们列出尽可能多的关于椅子和沙发的共同特征和属性。最后,他们得出结论:相似性与原型性之间存在着强烈的正相关关系,这意味着,当一个对象的特征与某一类别中的许多其他物品有大量交叠之处时,该对象就具有高度的类别相似性。
句子验证技术(Setence Verification Technique)要求受试者对真实的陈述回答「是」,对虚假的陈述回答 「否」,以衡量个人对对象进行分类的速度。研究发现,在处理高度原型化的物体时,如将苹果认定为水果,反应速度较快。而在处理像石榴这样不太典型的物体时,则反应较慢。这种对于更具代表性物体能做出更快判断的现象被称为典型性效应(Typicality effect)。值得注意的是,在这一认知过程中,观察到原型性较高的对象反应时间较快。
还有一种方法是示例法(Exemplar Approach),它认为一个概念由多个实例而不是单个原型来表示。这些实例是真正的类别成员,而不是抽象的平均值。使用这种方法进行分类时,必须将新项目与存储的示例进行比较。示例法和原型法之间的关键区别在于它们最佳应用领域:前者往往适用于较小的类别和具体情况,而后者对于较大的类别更有效。
分层组织
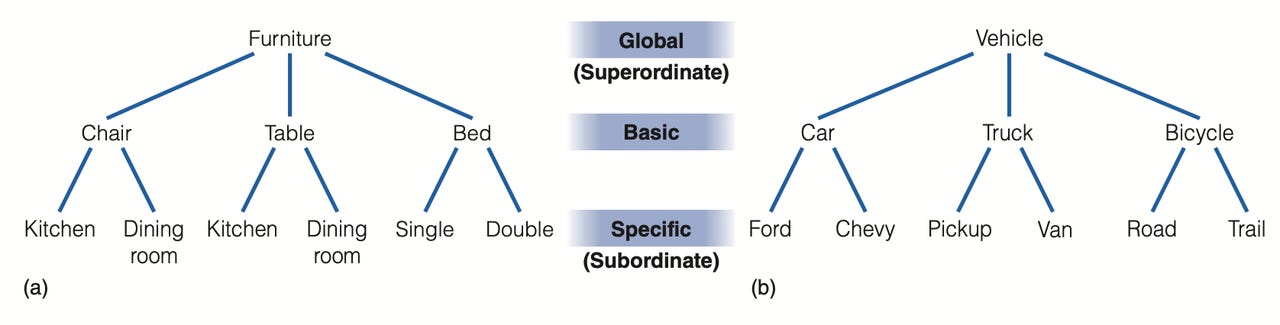
当讨论原型和示例法时,我们已经研究了类别及其成员的示例,例如各种类型的家具和椅子。这被称为分层组织 (hierarchical organization)。它通过将更大或一般的类别划分为更小或更具体的类别来定义。分层模型由三个级别组成:上位 (superordiante, 或者整体,global) 、基本 (basic) 和下位(subordinate,或者特定,specific)。
基本级是独特的,因为它可以过渡到上下两个级别。例如,当我妈想要从宜家购买床(基本级)时,我们跳过了所有其他区域直接去了床上用品区(上位级),在那里选择了我们喜欢的款式(下位级)。
Rosch 等人在 1976 年发现人们倾向于使用像鱼、吉他、裤子这样的基本名称;然而专家通常使用更具体的术语,而普通人或者非专家则通常坚持使用基本名称。因此,是否使用具体词汇取决于个体对某些对象的熟悉程度。
这种分层组织也常见于我们的生活,比如 OKR 方法论、思维导图等等。
一旦我们理解了这种层次结构,我们就可以进一步研究语义网络(semantic network)。这些网络将概念以与我们思维中的组织方式相似的形式排列。Collins 和 Quillian 在 1969 年提出,每个节点在这些网络中都代表一个类别或概念,并且它们是互相连接的,展示了我们思维中概念和属性的关联方式。在他们的模型里,类别可以按照不同层次结构进行组织——从宏观到局部。
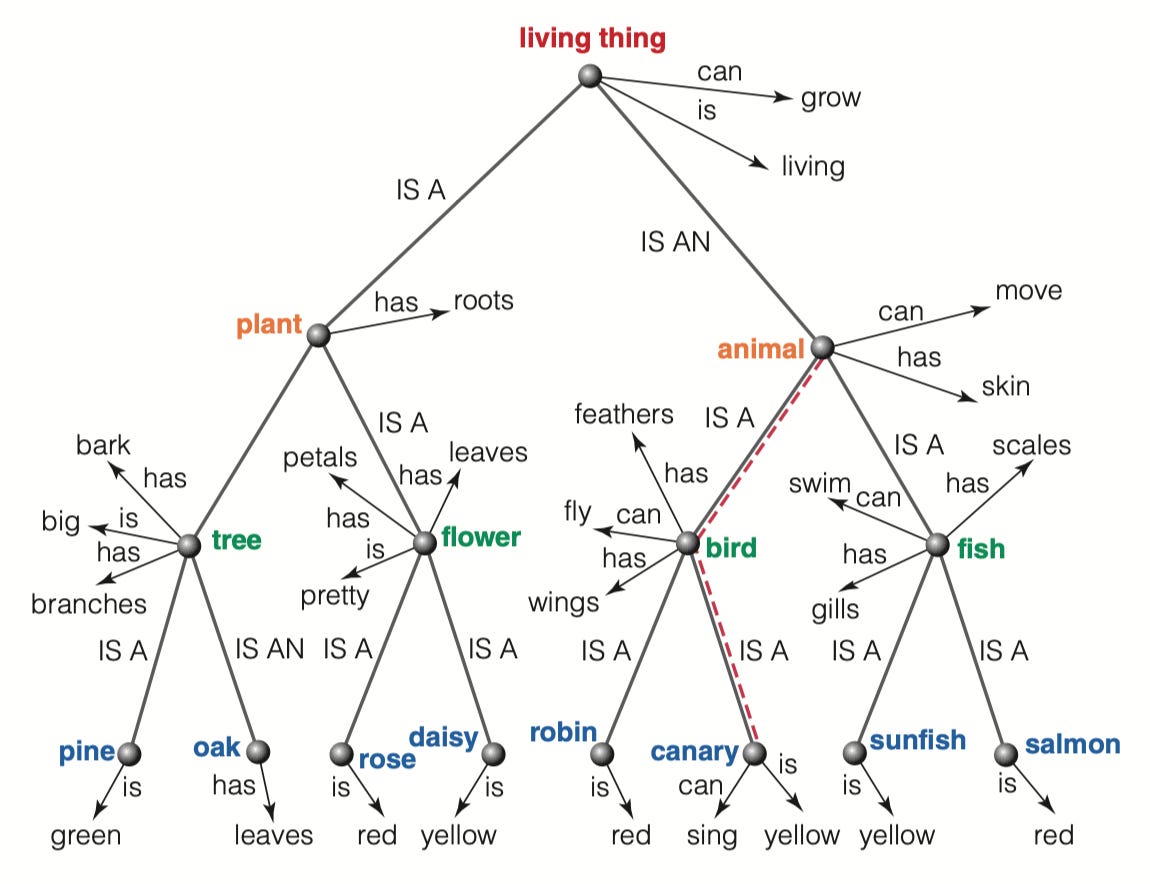
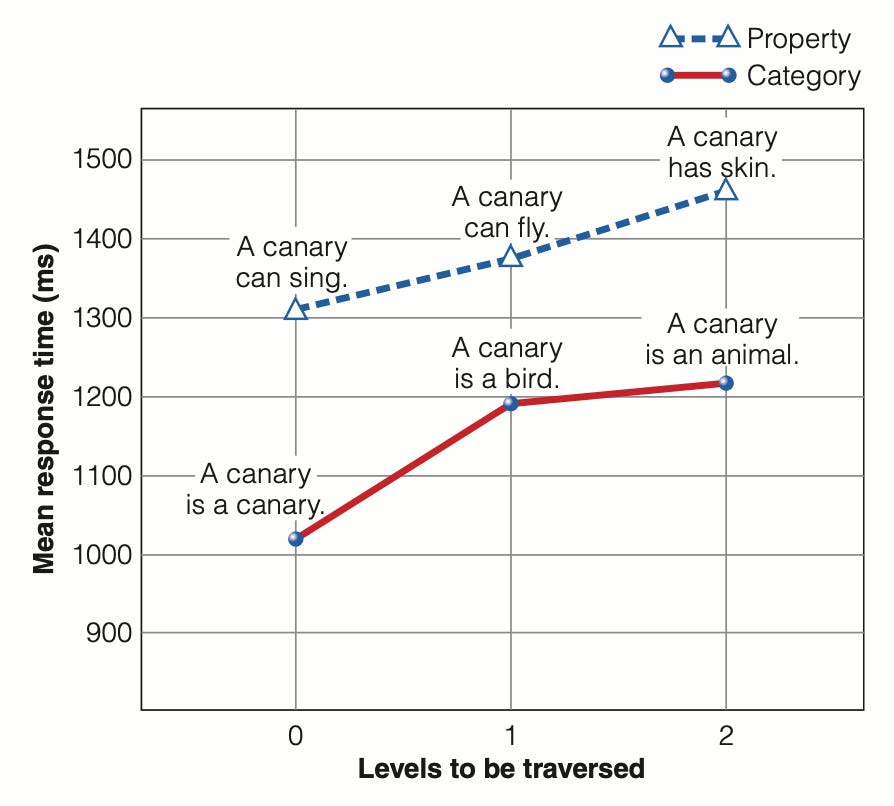
每个概念的属性在它们各自的节点上表示。通过沿着连接这些概念的线向网络上移动,我们可以辨别出额外的属性。例如,从「金丝雀」追溯到「鸟」会发现金丝雀拥有羽毛和翅膀,并具备飞行能力。同时还要考虑认知经济(Cognitive Economy)原则,它表明共享属性仅存储在更高级别的节点(higher-level node)中。
图表中,「会飞」属性低效地被分配给每个鸟类节点(如金丝雀、知更鸟、秃鹫等),这消耗了过多的存储空间。下属节点中标注了例外情况;例如,「鸵鸟」被标记为「不能飞」。研究人员还发现,一个人对概念的信息检索时间与通过网络所经历的距离相关,即较长的距离导致反应时间延长。
另一个理论是传播激活(Spreading Activation),这是一种沿着与已激活节点相连的任何链接延伸的活动。激活指的是节点的唤醒水平,接收到此激活的概念被启动,使它们更容易从记忆中访问。
当我们明白这个之后,我们似乎可以找到它们三者之间的关联了。
我自己的方法是,在白板中新建一个卡片,放大成为卡片,输入章节中所有的副标题、内容、高亮重点等等。于是,我得到了一张 global 的卡片。接下来,我会把每一个 toggle headline 拖拽出来,我得到了不同的 basic 卡片;再次浏览、拆分,我就得到很多了 specific 卡片。此时,我会将这些 specific 卡片组建成一个 basic 的 Section,添加标题。我们可以使用上述提到的三种方法(difinitional,examplar,prototype)标注这些它们。这些 section 也可以被包裹在一个更高阶的 section 中;而这些 section 中原来的 basic 卡片,也变为了 specific 和更加 subordiniate 的卡片。白板和嵌入白板也是一样的道理。被嵌入的白板也可以看作是一种 basic level 的白板,其中的 section 和卡片都是更加细节的等级……
我们能够看到的是,层级结构在 Heptabase 中是多元的,根据场景的不同自由变化。如此,对于我和其他的笔记小白,能够不假思索地快速记录和拆解知识,而不是被局限在传统的、枯燥的文本结构中。
当你的白板上的卡片数量不断增加时,你会遇到一个问题:不知道该不该创建新的白板。在刚开始使用 Heptabase 的时候,我不太喜欢在白板中嵌入白板,所以也是利用 Section 去归类的。我试图模拟这些知识在大脑中的情景。我不是什么记忆冠军,所以我的大脑里没有什么记忆宫殿或者什么文件夹之类的,只是一个无限延展、海纳百川的地方——这就很像 Heptabase 的白板。但是,随着容纳的卡片越来越多,输入和滑动白板开始变得异常卡顿。官方人士告诉我,目前单个白板推荐最多放 150 张卡片左右。不过,在我的实际使用中,当一个白板大于 200 张卡片的时候,才会卡顿,不流畅。于是,我这才开始考虑嵌入白板。
我的伦理课程每周需要读伦理守则,每一个守则老师都会单独讲一下,所以也都有相应的笔记;于是,我把每一条规则都摘录到 Heptabase 中当做卡片。如果不内嵌新的白板的话,那么现在这个白板会变得非常卡顿以及更为臃肿。于是,我新建了内嵌白板将它们放了进去。
另一种情况是,我每一个章节(大概 30 页)的内容大概都在 20 张卡片左右,有一章内容非常重要和庞大,要看 60 页数左右的教科书(一般每章 30 页)。所以,我也为这一章新建了内嵌白板。
就这样,Section 和内嵌白板的逻辑关系可以这样表达:
当一个 Section 中的卡片数量大于 25 张卡片的时候,我们便可以将这个 Section 转化为一个内嵌白板
当你需要创立 Project 的时候,可以内嵌白板
颜色
当我们处理完文字内容和整体的结构之后,我们使用颜色突出重点的内容和对象。
我按照内容的特点区分对象的:
红色:最重要
橙色:重要
黄色:一般重要
绿色:特别的东西(比如时间线,或者是和自己想法迥异的知识)
蓝色:相关的问题或者图表信息
紫色:词句高亮(偶尔用黄色)
灰色:不是很重要的,具有辅助作用的其他信息
颜色标注的过程是自上而下,由外至里,从广至狭。当我们为对象标注颜色的时候,我们其实已经完成了短期记忆中的排演(rehearsal),也复习了(review),从而也不自觉地加深我们对这些对象的印象。
如果白板中,相同颜色的对象太多了怎么办?那么,它也许说明了两个部分:
这些对象对我们太重要了,我们需要及时回顾
有可能滥用了某一种颜色。你需要重新审视和评判这个白板中的内容。重新评判卡片或者 Section 的重要程度。这个情况下,你需要仔细且勇敢断舍离。
链接
了解了分类、对象和颜色,我们其实可以开始重新整理、排布我们的对象。
不过,只考虑分层结构是不行的,它也存在着缺陷。
尽管 Meyer 和 Schvaneveldt 在 1971 年的研究表明,从记忆中回忆出一个单词可以激活网络中相邻区域,但这个模型有其局限性。具体而言,它未能解释典型性效应——为什么我们比「鹦鹉是一种鸟」更快地验证「鸵鸟是一种鸟」。
认知经济的有效性受到质疑1,因为一些个体可能更倾向于将特征「有翅膀」归属于「金丝雀」,而不是「唱歌」。
所以,研究者们发现了另一个理论,称为连接主义方法(Connectionist Approach)或并行分布处理(parallel distributed processing,PDP)。这种方法用于创建代表认知过程的计算机模型。这些模型中的圆圈象征着单元,旨在模仿我们大脑中的神经元。
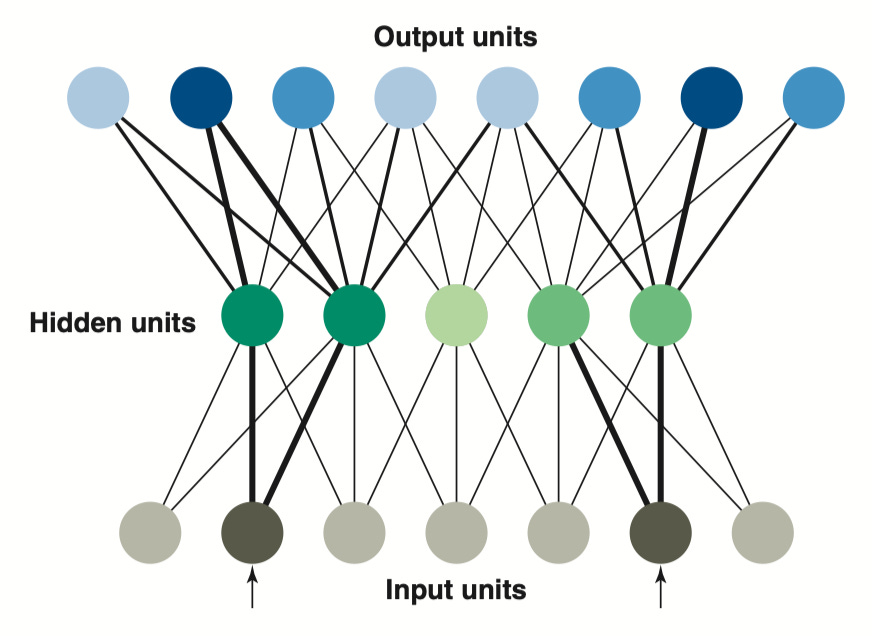
这些单元通过不同的活动模式在网络中表示概念及其属性。线条描绘了对象之间的连接,使得单位之间能够进行信息交流,类似于大脑中的轴突。其中一些单元可以受到环境提示或其他单元信号的刺激。被环境刺激激活的单元称为输入单元。在这个简化的网络模型中,输入单元向隐藏单元发送信号,然后由它们传递给输出单元。
连接权重(connection weight)决定了从一个单元到下一个单元的活动放大或减少,类似于神经元之间突触的信号传递。较高的连接权重代表着更强烈地刺激后续单元的可能性,而较低的权重则意味着刺激程度减少。负权重则表示会降低兴奋度或抑制激活。
网络单元的激活取决于两个因素:(1)来自输入单元产生的信号,以及(2)连接权重在整个网络中的传播。
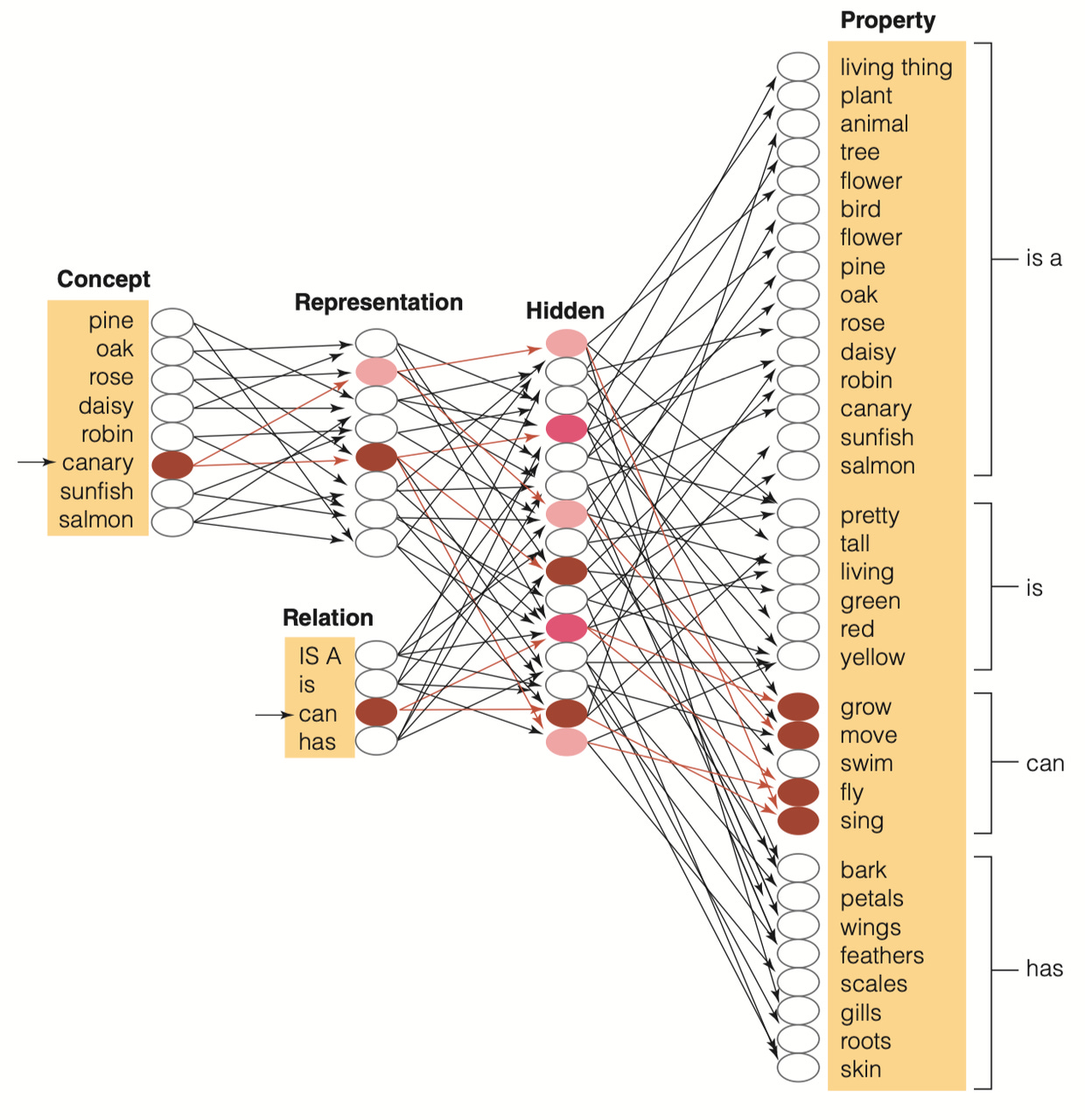
这个图示说明,当"canary"(金丝雀)和"can"(能够)两个项目单元被激活时,会引发整个网络的活动。这将导致与“金丝雀可以”相关的属性单元如生长、移动、飞翔和唱歌被激活。
于是,我们便可以用 Arrow 连接这些对象。这不仅能够具象这些对象之间的关系,也给我们的大脑带来一定的指引,激活对象之间更快、更活跃的联想。另一个显性的链接是 Mindmap。Mindmap 不仅能够展示单个细节,也可以绑定相互依赖(interdependent)的卡片,从而获得针对某一个卡片更加详细的辅助内容。而为对象提供隐形链接的双链,能令我们在输入的时候,快速连接可能相联的对象。
Arrow
在一开始,Arrow 很容易被滥用,这使得白板页面十分混乱。我自己回顾的时候,也摸不清头绪。直到今天,我才开始使用 Arrow 指明对象关系。
我们可以通过线条的粗细程度和虚线表示对象之间的关系密梳和所需相对注意力的多少。线条越粗,表示对象之间的关系更紧密,需要的付出的注意力便越多;线条越细,表示对象之间的关系更疏离,不用付出太多的注意力,知道就行了;而虚线代表的则是对象关系不强,可以知道也可以不知道,偶尔看看;持一种假设的态度。
我为自己使用 Arrow 创立了三个原则:
对象之间必须有距离
对象本身具有独立性
标注已经意识到的对象关系
只有同时满足这三个条件的时候,我才使用 Arrow。
当我摘录书籍或者教科书的内容时,我会拖拽不同的内容;因为这些内容(比如特定的术语、章节名称、章节中的副标题等等)具备了独立性,但同时它们在文本中的关系颇为紧密。
当对象之间的关系本来很紧密的时候,比如都在同一个副标题下,或者是上下文的关系时,我便不会用 arrow 连接它们,而是以 bento 的形式紧靠每一个对象。
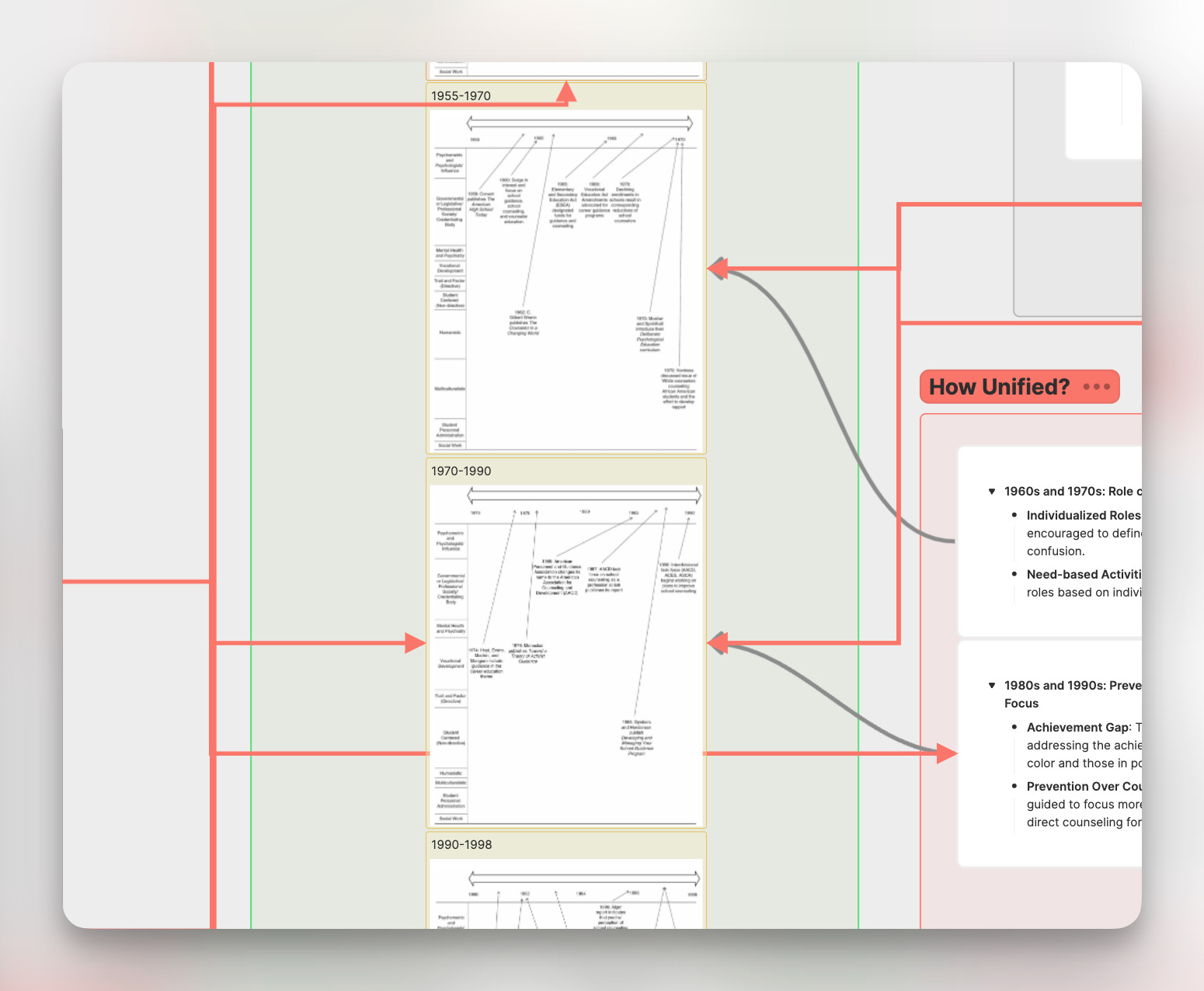
当我们在回顾并排布对象的时候,我们一定要同时注意我们大脑中发生的事情。当我拖拽卡片出来的时候,我的大脑已经告诉我它们之间的关系是什么了,所以我直接在 Arrow 上文字标注,并和对象相连。在上图中你可以看到,我使用了大量的粗线,这是因为与时间轴相联的卡片是该时间下发生的事件。

另外一种显性的对象关系表达是 Mindmap。传统的 Mindmap 并不好用,也可能不能帮助我们的学习。
在我个人的体验中,XMind 太注重设计,也太花哨,并不好用;Mindnode 虽然间接,但也需要我自己去不断调整和设计,而非专注在内容上,输入体验也不方便。虽然幕布是我认为是这类软件的佼佼者,让我可以专注在内容上,但我在输入或者回顾的时候会考虑排版问题。比如,如果我这一部分输入了几百字,那么最终分享的图片上的子主题中的内容也非常高。所以,我的注意力会脱离内容本身,而去关注一些旁门左道。
Heptabase 的独特之处在于,它将 Mindmap 扩展到卡片上。我现在可以将卡片变换为子主题,一个包含详细补充内容的子主题。它可以折叠、展开、拖动,甚至可以用 Arrow 链接其他内容;而不再是以前那种傻乎乎的形式。我们也可以创建具有一定顺序性的卡片。
在实际使用中,你可能会像我一样对容易搞混这两个,因为它们看上去似乎都是在链接对象罢了。它们唯一的区别是对象独立性。在 Arrow 中,每一个对象都是自由的,可以随意挪动;对象之间似乎有种自由选择权。不过,在 Mindmap 中的卡片似乎持有一种命定论,它们只能围绕着某一个主题存在,并且不可脱离。它们之间的关系更加密不可分,牵一发而动全身。

什么时候使用 Mindmap 是一个不好定位的问题。在我看来似乎只有两点:1)简单的概念分类,比如简单的一两句话或者单词;或者是简单的层级性,比如灵活性不强的公司架构等;2)因为这样的对象独立性也不会很强;3)具有一定的顺序性,比如时间轴,或者步骤。
我之所以不常用 Mindmap 的另一个原因是,它目前无法像其他软件那样更改排列样式。此外,Mindmap 的灵活性较低,与我的笔记理念不太匹配。你能看到的这些例子,都是我在过去六个月的笔记中能拿得出手的了。

双链
除了明显的连接之外,还有一种隐形连接:双链。
之前在使用 Notion 类型的软件时,即使我看了很多关于双链的文章,我还是不太明白它到底是什么。不过,我终于在 Heptabase 上面弄明白了这件事情。
我第一次使用双链的时候是用它整理教材中的术语表,在一个卡片里面放进了将近 400 个术语,把我电脑搞得崩溃了(现在不会了)。当时我在想,这样一来,每个词语都是独立的、可操作的个体。
后来,随着输入的笔记和知识卡片越来越多,以及越来越频繁地使用上述的排布,我发现我在输入某个内容的时候,有时候能够隐约或者明显感觉到之前好像有过类似的知识。于是,我用「@」唤起并检索关键词,便可以快速链接这些对象;甚至可以直接新建卡片。这种顺滑的体验就像之前使用闪念胶囊一样,能迅速记录那些瞬间的想法,避免了因未能记录而产生的痛苦。
更重要的是,Heptabase 支持拖拽成卡。这是一个「用了就回不去」的功能,也大大地提升了体验。
我现在已经离不开双链了。只要内容中某一个关键词或者主要内容引发我脑海中的联想,我必然会用它看看是否有相关的概念。
Tag 和搜索
我很喜欢 Heptabase 中的 tag。他终于回归了纯朴的样子:简单的标签。我始终觉得,不管 tag 发展多厉害,手打标签的速度永远比不上我们大脑给内容自动打标签分类的速度。对于使用标签的人来说,要么遵守既定的标签规矩,要么只能创建越来越多的标签;一旦如此,不仅可能在未来遇到如何管理标签的困境,也不可避免地滥用标签。
标签也可能会强化我们的标签思维。时间长了,我们用标签明明我们所有的事物,比如我们将网络上或者现实中看到的人事物都习惯性地贴标签;也会局限我们的思维和卡片本身的自由。比如,Flomo 将 tag 做成了层级的内容,它用父子标题替代了父子卡片关系,将单个卡片锁死,从而消除了我们意识到卡片之间链接的可能,从而产生知识碎片之间的巨大鸿沟。逐渐地,我们只是将它作为一种分享内容的方式。Supernotes 和 Tana 也有这样的问题。
相比之下, Heptabase 将所谓的父标签改为了更便捷的 Group。如此一来,我们可以在 Heptabase 中更灵活地实施 PARA (项目、领域、资源和归档)系统。如图,我的 Psychology 小组中很多东西。有 Newsletter(电子报)项目,有发展心理学、实验、治疗技巧等各种领域,这些卡片都可以成为我的资源,还有归档的术语(general term)和 drug 之类的。
我习惯在回顾是整理白板或者卡片盒中的内容,并给一些特定的卡片或者是 PARA 需求的卡片打上标签,以防滥用。如果你不习惯这样的方式,Heptabase 为我们提供了另一种选择。你可以像使用 Notion 或者 Notion-like 软件一样,将它看作一个 Database,毫无障碍的使用它。于是,Heptabase 让鱼和熊掌亦可兼得焉。
Heptabase 的搜索功能真的是锦上添花。Notion 的搜索非常难用,颗粒度也不是很细节。不管我们怎样分类去管理,当我们回忆细枝末节的时候,也比不上搜索的快速和便捷。好用的搜索功能是所有笔记软件必须重视的,而 Heptabase 做的最好。它不仅可以使用快捷键可以全局搜索和搜索指定的白板,搜索范围覆盖齐全,既可以预览卡片内容,也能搜索 Tag、Section、和 Whiteboard,能让我们更加精确地搜索和连接内容。
FREEDOM 特性
如果要用一个词语总结 Heptabase 的特性,我想一定是自由。我们可以在其中体验到前所未有的自由感,而非被局限在某一种框架内。我们不仅可以高亮文字内容或者给赋予卡片颜色,还可以探索对象之间的逻辑关系,根据自己随意摆放卡片的位置。当我们像小孩一样摆弄这些「玩具」和赋予它们属性的时候,我们潜移默化地多次回顾了这些知识,在不知不觉中,加深了我们对它们的印象。
当这样做的时候,我们可能会发现自己完全专注在内容上,从而忽略了时间的流逝。这便是它的 优势,即「帮助用户更好地学习,而非帮助他们打造生产力系统」。用户打开软件便可以快速「进入到心流状态,专注在学习和研究他们在乎的主题上。从而忘记他们其实正在使用一个软件」。
我们高性能表现是 100% 专注,那么心流则是 110%。
专注 Focus
专注的定义是一种专注于环境中特定刺激或位置的能力。我们都知道,正常人是不可能记住所有东西的,会忘记一些无关紧要的事情——选择性注意力。不过,随着信息的发展,FOMO 诞生了,人们开始担忧自己错过了某些当下看似重要的东西。为了害怕自己遗忘,很多收藏工具也被开发了出来。我们所做的并没有帮到我们学习,而只是安抚了当时的恐惧和心慌。它们只是被我们放进收藏中吃灰,并没有被存在我们的记忆里。这是因为我们大脑中有一种过滤机制,将「无用」的信息过滤掉,从而让我们更好地专注于当下的事情。下面的两个模型能更好地帮助我们理解这个过滤机制。
Broadbent's Filter Model(布罗德本特过滤模型)
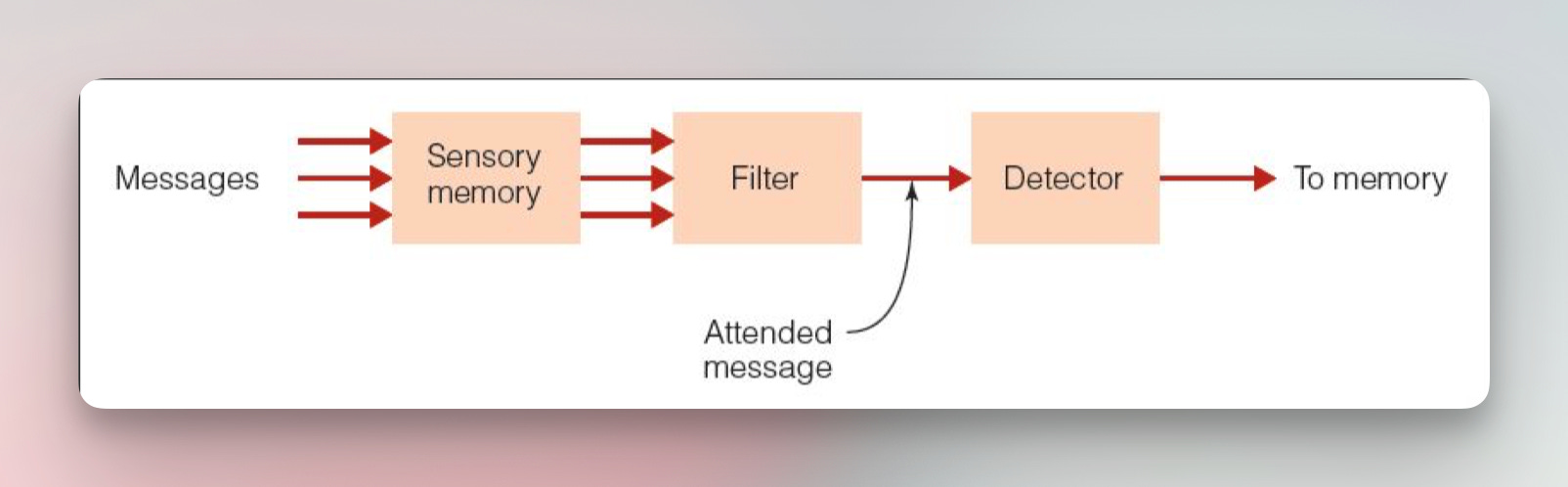
这个模型中,感觉记忆在将所有传入信息转移到过滤器(Filter)之前,会短暂地保留这些信息。该过滤器根据其物理特征识别相关的消息,并且只有选定的消息才会传递到下一个阶段——检测器(Detector)。然后,检测器处理此信息以确定消息的更高级属性。随后,短期记忆从检测器接收此输出,并在可能将其转移到长期记忆之前保留10 至 15 秒钟。

有两个例子:
鸡尾酒会现象:你是否曾经在一个嘈杂的派对上,参与一场谈话,突然间听到房间另一边有人提到你的名字时,你会立刻注意过来?
「亲爱的阿姨简」的实验(Gray & Wedderburn, 1960)中,参与者被告知要跟读左耳听到的信息。但他们报告称听到了一条信息:「亲爱的阿姨简」,这条信息从左耳开始,跳到右耳,然后又回到左耳。
Treisman’s attenuation model(特里斯曼衰减模型)
这样的实验结果启发了特里斯曼,他搞出了一个新的模型:
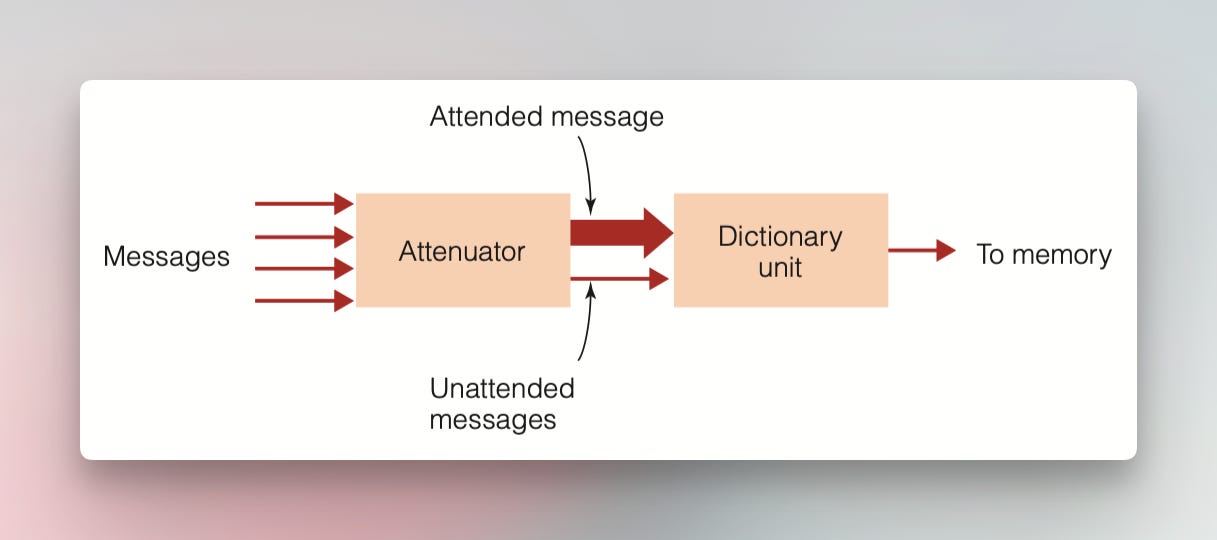
在这种模式中,有关注的信息(attended message)可以在信息处理系统的早期与无关注的信息(unattended message)分离,而信息的选择则在之后进行。
这种模式包括两个部分:衰减器和字典单元。衰减器取代了布罗德本特的过滤器,并根据心理特征(高音或低音、快或慢)、语言(音节或单词的组合方式)和意义(词序如何形成有意义的短语)对接收到的信息进行分析。
关注的消息以全强度通过衰减器,而不关注的消息则以显著降低的强度通过。词典单元存放具有激活阈值的单词。常见或重要单词具有较低阈值,而不常见的单词具有较高阈值。这样就是为什么当你背单词的时候,一些看上去很奇怪的词汇背起来比看上去正常的词汇要容易的多。
现在已经有很多更新更好的解释模型,所以不再详细展开。我们可以假设,在某种情况下,Heptabase 填补了这个衰减模型的空白。
我们通过标注、高亮、整理对象结构和关系,将信息筛选并分类为重要且需要注意的信息以及不需过分关注的信息;也让所有的消息尽可能地通过筛选器。因为这样,我们在 Heptabase 上付出的注意力和时间会越来越多,我们越可以记得住大部分存留的内容,而不是像其他笔记工具一样,只是存入知识,但我们无法提取它们。
负载
我们再来看一下注意力的负载能力。
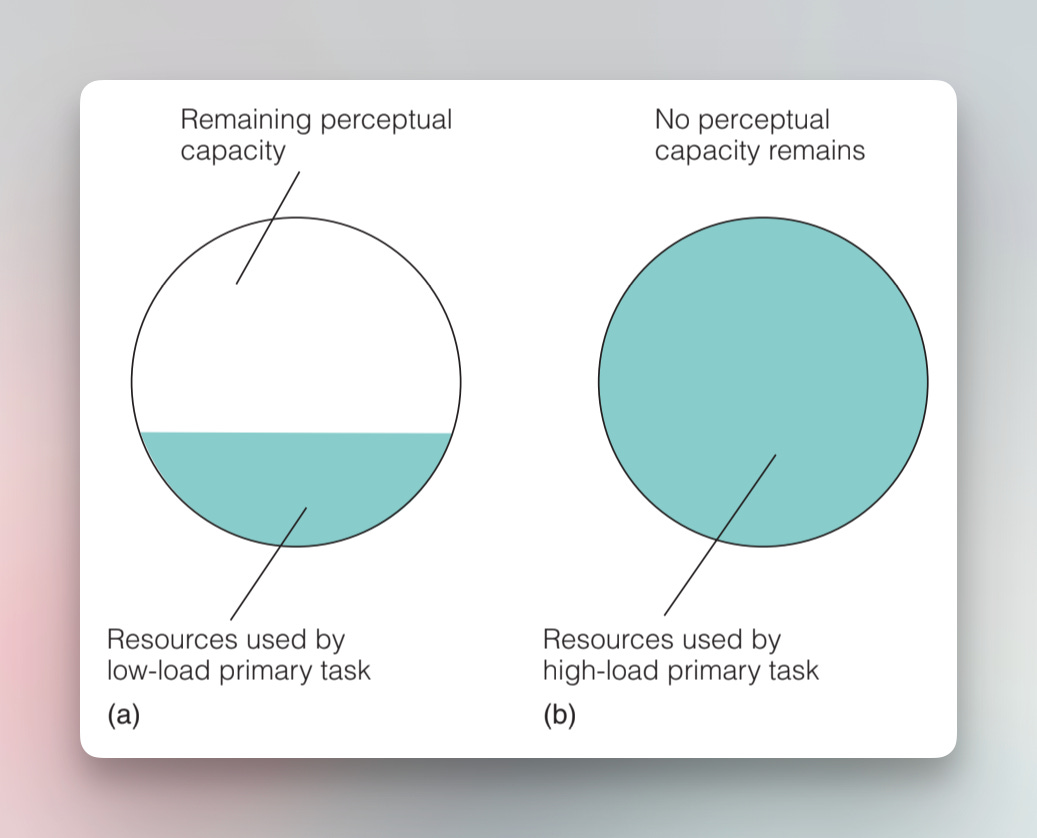
处理能力是指个体在任何给定时间内可以管理的信息量。术语「感知负荷(Perceptual Capacity)」用于表示特定任务的复杂性。高负荷任务更具挑战性,消耗较大的处理能力,类似于计算机中的RAM。消耗较大的处理能力,类似于计算机中的RAM。这意味着没有剩余资源来处理未关注或无关刺激,从而降低了分散注意力的可能性。另一方面,简单的任务具有低负荷,并且使用较少的处理能力,可能会留下可用于管理未关注或无关刺激的资源。
研究人员发现,与简单任务相比,更复杂的任务会导致反应时间变长。在处理需求较低的任务中,有额外的处理能力可用于处理与任务无直接关联的刺激。比如 Stroop Effect。

说出词汇可能会干扰我们辨认其墨水颜色的能力,因为忽略单词的意义对已经讲阅读单词这项任务自动化的我们来说是具有挑战性的,因为它们需要注意力。
此外,对显性注意力(overt attention)的研究涉及使用眼动仪等工具来测量眼球运动。这个过程的两个关键组成部分是扫视——从一个点迅速转移到另一个点——和注视——在感兴趣点上短暂停留。我们的眼球会停留在视觉上突出并吸引注意力的区域。这种突出取决于刺激物的特征,包括颜色和动作,这些都是非常显著的因素。这些高显著性区域吸引我们最初的一瞥。这也是为什么,我们要用不同颜色在白板上标注卡片,如此一来,我们的注意力能够一下被吸引,且优先查看这些卡片。
所以,在这个自由之下,我发现了更多的特点。F 代表 Focus(专注),「我们越专注,做得就越好」。R 代表 ReThink,意思是重新思考。每当我使用 Heptabase 的时候,我都能从这些内容中获取新的想法,哪怕是一点点;就算没有新的想法,我也能再次思考他们,加深我对这些对象和内容的印象,巩固我的记忆。
平均而言,我们的思维大约有 20% 到 40% 的时间在游离。思维漫游对于创造性洞察力来说是非常重要的。创造过程要求首先收集信息、关注问题、真正专注,然后放松……科学和数学领域充满了那些只是在淋浴时胡思乱想、上公交车或遛狗时突然想出令人难以置信解决方案的人物形象……这是因为在思维漫游期间,我们能够以一种新颖且具有价值的方式将远距离元素联系起来。这就是创造行为的定义。
不过,这些知识一开始是互相缠绕 (Entangle) 着的,仿佛一团乱麻。所以,我需要参与(Engage)进去,开始梳理这些知识,和它们互动,不让它们纠缠,而是它们合理地缠绕于我,为我所用。如此一来,我便完成了对任何知识的祛魅(Disenchant);O 代表组织(Organization),我将这些知识合理有序地组织起来。随着不断地累计知识,花的时间和注意力越来越多,我也能够成为某个领域的「专家」,即 M 代表着 Maestro 大师。
使用 Heptabase 的方法:U.R.E.A.D.C.(You Read Context)
Uninterrupted typing 不间断地输入
我们首先创建一个白板。每次在这个白板输入,先创建一个卡片,不间断地输入。我们只需要专注内容,而非设计或者排版。
The more disrupted is particularly for young people, the harder it is for them to grasp, to build the cumulative mental models that amount to master in any subject. 尤其是对年轻人来说,越是混乱,他们就越难掌握,也就越难建立相当于掌握任何学科的累积心智模式。
Review 回顾
当我们输入完毕之后,我们需要从头到尾回顾内容,并且修改、增删内容:
加粗文字
高亮词句
哪些内容需要变为折叠列表,可以成为卡片的
哪些内容与其他卡片相关的,需要用双链补充的或者需要被创建为双链
……
Extract 抽取
将您认为的内容抽取出来成为新的卡片。
Arrange 排布
排布这些新的卡片
Determine 决定
决定对象关系
创建 Section 和 Embedded Whiteboard
用颜色标注、区分对象的重要程度
connect Context 连接内容
使用 Arrow 凸显对象关系
连接并标注对象之间的关系
通过这六个步骤,我们详细分析了一个宏观对象,如一篇文章、视频或书籍等。因此,我们不仅对该对象有更加深入的理解和发现,也在全局上对该对象更了如指掌。于是,不管是回忆还是应用其中的某个知识,得益于搜索和管理,我们能够快速应用起来。所以,我们才能更精确地、更专注地学习这些内容。UREDC 也可以称作 You Read Context,即你读懂了上下文。
当我们使用这 6 个步骤的时候,我们又回到了专注状态。
如果你要执行,如果你要把想法付诸实践,那么你就必须回到专注的状态。
得益于 Heptabase 的可视化特性,我们可以清晰地看到对一个项目或者知识点日积月累的成果。我们也能意识到,笔记是渐进式的、不断进化的;比如更改对象之间的联系,为以前的卡片添加双链、标签等更多信息。
于是,时间久了,透过这些笔记,我们看到的其实是无限进步的自己。
展望
在刚开始动笔写这篇文章的时候,我还是谈了谈之前的 AI Assistant 的。它和现在的 Notion Q&A 和 Google NoteBookLM 很像,保护隐私的情况下,检索卡片,推荐更贴合你问题的卡片。不过,体验一般,几乎没怎么使用过。但我还是很期待未来 AI Assistant 能提供带有引用(citation),且能够跳转到具体卡片、Section、Whiteboard,更大程度上提升搜索功能。
其次,如果 Heptabase 可以使用 AI 根据白板内容,生成一些问题 Section,也许能大放异彩;或者在后期开放多人协作的时候,能用 AI 根据某一个卡片头脑风暴等等。参考案例在 这里。
我想大多数都是因为卡片的特性才喜欢上 Heptabase 的。如果 Heptabase 在移动端新建页面改为新建卡片,比如 Flomo 或者 Supernotes 的卡片输入,会令我个人更加喜欢。另一个展望是可复制分享的白板到自己的Heptabase,就像 Notion 那样。
我也希望未来 Heptabase 能在设计上多下点功夫。虽然 Heptabase 的实用主义设计目前还算不错,但其美观性稍显不足。对于注重设计的用户,他们可能会被 Scrintal 所吸引——我当初就是这样。一些动效、页面的颜色、元素的设计等等。
不过,我后来还是回到 Heptabase 了,因为 Alan 的团队理智地取舍用户的建议;我也看了 Alan 当时的博客,其中的对于 Heptabase 有一个较为清晰且可实行的理想。
当然,虽然很多功能还是民主的,但令我感到忧心的是,在未来的成熟期中,随着用户基数和团队不断扩大,一些功能的民主性也是需要谨慎考虑的。这一点需要克制。所以,我特别欣赏 reMarkable 的一点是,他们的团队会根据自身核心理念来考虑用户提出的功能建议,这也正是我希望 Heptabase 能做到的。不过,这种在 社区 里的投票,也让用户有了「参与感」。
最后
Heptabase 能否代替纸笔?
不能。任何软件都不能替代纸笔,Heptabase 也不例外。打字赶不上我们的思维和烂笔头。当遇到大的项目的时候,我可不是一上来就坐在电脑面前,打出大纲,然后坐在那里发呆;而是先在 Stalogy 笔记本上写下大致的构思,画出基本的网状图,即使潦草,但能看明白就行。有了一个基本的脉络,我再去 Heptabase 中是有UREADC 六步法记录和厘清它们,再整合到一起。所以,我现在出门随身携带 Stalogy 和 斑马的 Pitan 笔。

价格
单月付费 11.99 美元/月,107.88 美元/年(合 8.99 美元/年)。
如果你看完本篇文章觉得 Heptabase 可能是你的「终极」知识系统,不妨按照我的方法,体验 7 天,不满意再申请全额退款即可。有可能你也会找到属于你的学习方法。
感谢
感谢你读完此篇,不知你是否对这款软件有了一种新的认识。Heptabase 是集易用性、灵活性和卓越的用户体验于一身的软件。不管你是擅长于哪个专业或者方向,Heptabase 总能够帮到你。
它的自由 F.R.E.E.D.O.M. (Focus, ReThink, Entangle, Engage, Disenchant, Organize, Maestro)和 U.R.E.A.D.C. 六步法在某种程度上激发了我们使用工具时候的创造性、对知识的完整梳理和深入了解、强化了我们对于内容的专注程度,最终加深了所掌握的知识记忆。
我虽然不喜欢第二大脑这个神秘化的词汇,但我愿意只把这个词汇颁发给 Heptabase。我也可以大胆地说,它就是我的终身学习知识系统(而非笔记系统)。
如果你想试试重获自己专注的能力,不妨试试 Heptabase 吧,也许令你有所收获!
尾声
就在快要写完这篇文章的时候,我的朋友分享了一篇 Ness Labs 采访 Alan 的 文章。我浅看了一下,其中不乏志同道合之处,也有令我感到佩服的地方。
Alan 在采访中也分享了两个指导原则,也恰恰回应了我最后一部分关于决定软件功能的展望。
他说道:
The most important principle in our company is that we want to ensure that everything we’re building is aligned with our ultimate goal of helping people acquire and establish a deep understanding of the things they care about. We’re very conscious of not getting distracted by other purposes. The second principle is that we want the product to be as friendly and intuitive as possible. Our target users should be able to get into the flow of thinking as soon as they open the product.
我们公司最重要的原则是确保我们所构建的一切都与我们的最终目标相一致,即帮助人们获得并建立对他们关心的事物的深刻理解。我们非常清楚不要被其他目的分散注意力。第二个原则是我们希望产品尽可能友好和直观。我们的目标用户应该能够在打开产品后立即进入思考的状态。
与其说是 Heptabase 吸引我,倒不如说是 Alan 本人的思考更吸引我。他所表达的思考是我所喜欢且相信的。所以,我也相信 Heptabase 这款软件从而做了一笔对于学生的我来说「不菲」的投资。就像我在文中描述的,它带给我的价值和潜在价值是无可估量的。
后来,我也浏览了其他有意思的文章,比如 PJ Wu 分享了 Heptabase 完整功能介紹 - 以卡片和白板為基礎,最能讓你進入心流的視覺化學習軟體,以及王翰元也分享了使用 Heptabase 的 反思 并觉得这个 Heptabase 所强调的「价值」一词略感违和;Alan 也将自己的思考集放进了 Heptabase Public Wiki 中。
你也可以用 Heptabase 创建属于你的智识界。
例如,「一只猪是哺乳动物」的反应时间(RT)为 1,476 毫秒,而「一只猪是动物」的反应时间为 1,268 毫秒。然而,在理论上,「一只猪是哺乳动物」应该被更快地连接,因为「哺乳动物」和「猪」直接相关(Rips et al., 1973)。